本人长期出售超大量微博数据、旅游网站评论数据,并提供各种指定数据爬取服务,Message to YuboonaZhang@Yahoo.com。同时欢迎加入社交媒体数据交流群:99918768
前言
最近在做机器学习下的人脸识别的学习,机器学习这个东西有点暴力,很大程度上靠训练的数据量来决定效果。为了找数据,通过一个博客的指导,浏览了几个很知名的数据集。
几个大型数据集是通过发邮件申请进行下载,几个小型数据集直接在网页的链接下载,还有一个Pubfig数据集则是提供了大量图片的链接来让我们自己写程序来下载。
权衡了数据量的需求,最后选择Pubfig的数据集,于是就自己写了一个python图片采集程序,里面用了urllib和requests两种方法.
分析Pubfig提供的下载文件的特点
这个数据文件提供了在数据集中出现的所有人物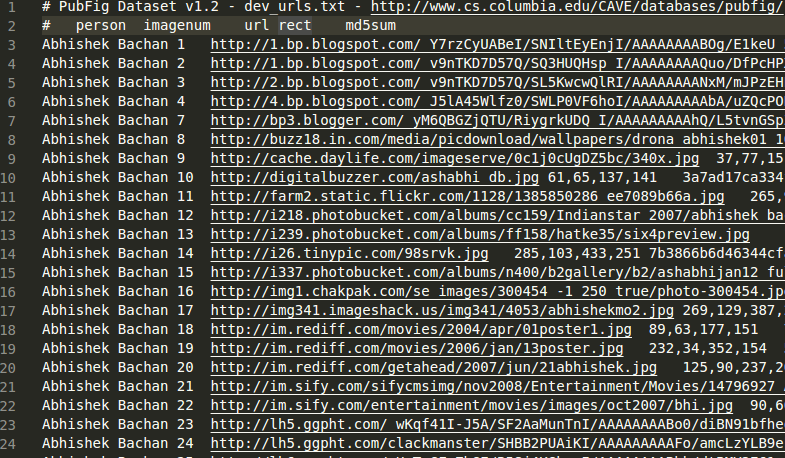
这个数据文件提供了每个人的urls
可以看出来这个数据集的处理其实非常简单了,可以通过readlines的方式存进列表用空格分开一下数据就可以把urls提取出来了。
处理一下urls文件
urls在文件的中后部,写个文件把它单纯地提取出来,方便使用。
我单独把Miley_Cyrus的部分提取出来放了一个txt文件
1 | pic_url = [] |
爬取urls图片
1. Urllibs方法
1 | import urllib.request as request |
2. Requests方法
1 | import requests |